NAT
NAT translates the private IP addresses inside the enterprise into public IP addresses visible on the public Internet. In most cases NAT is combined with firewall into one device.
NAT is classified in two ways:
- mapping
- filtering.
NAT mapping can be endpoint independent, when it uses same external mapped address (or rather a combination of IP address and port) for packets from a device behind it, which are destined to different endpoint in the internet.
Example
Internal endpoint sends a packet with source IPi:Pi and destination IPe1:Pe1 and to destination IPe2:Pe2 (IPi – internal endpoint IP address, IPe1 and IPe2 – external endpoints #1 and #2 IP addresses, Pi, Pe2, Pe1 are correspondent transport layer ports).
NAT statically maps IPi:Pi to IPnat:Pnat in both cases, so external endpoint #1 gets a packet with source of IPnat:Pnat and destination of IPe1:Pe1 and #2
with same source of IPnat:Pnat and destination of IPe2:Pe2
In contrast there is an endpoint dependent mapping where NAT maps IPi:Pi to IPnat1:Pnat1 for endpoint #1 and to IPnat2:Pnat2 for endpoint #2
NAT filtering can be Endpoint-independent, Address-dependent and Address- and port-dependent.
Endpoint-independent filtering allows any internal endpoint with any source port to communicate to internal endpoint once NAT binging is established by the latter.
Example
Internal endpoint send a packet with source of IPi:Pi to destination of IPe1:Pe1 to external endpoint #1.
NAT translate IPi:Pi to IPnat:Pnat. External endpoint #1 send a packet back with source of IPe1:Pe2 to NAT IPnat:Pnat and packet goes through NAT and reaches internal endpoint.
At the same time external endpoint #2 can send a packet destined to the same IP:port pair (IPnat:Pnat) and NAT would allow it to pass and eventually reach internal endpoint too.
Address-dependent filtering won’t allow this situation. It won’t let a packet from external endpoint #2 destined to IPnat:Pnat get though. However it would let external endpoint #1 to establish a new session with source of IPe1:Pe3 toward internal endpoint.
Address- and port-dependent filtering will close this breach – only one bidirectional session is allowed in this case.
Most of NAT devices are using endpoint-dependent mapping and address- and port-dependent filtering and are called symmetric NATs.
NAT complications for IP telephony.
1) External endpoint cannot connect to internal endpoint until the internal one creates a NAT binding.
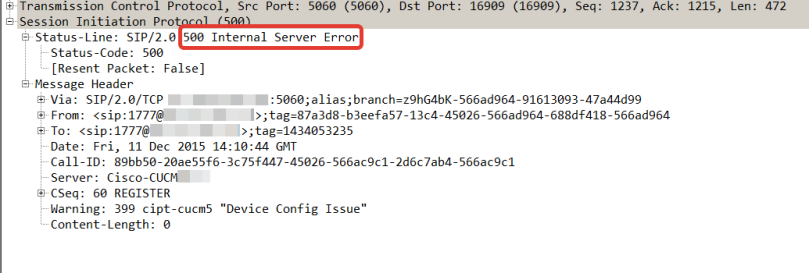
2) SIP signalling carries an information of what IP address and port to use. So when lower network protocols tampers with IP address and ports SIP negotiations fails.
3) NAT bindings times out and can be restored only from behind the NAT while SIP endpoints can be both servers and client in a SIP dialog and rely on the fact that any of them can start a transmission.
Solutions
There are a number of solutions that can be applied in different situations.
NAT ALG
In addition to creating a binding NAT can inspect a call signalling and fix it appropriately. But you must be sure that your NAT device firmware is up-to-date with all signalling protocols. Moreover it cannot work with encrypted traffic so forget about secure SIP.
Rport and comedia
RFC 3581 gives support to a rport parameter in SIP Via header which instructs a remote endpoint to send signalling to destination if got from network layer.
Example
Asterisk has a a nat=force_rport and nat=comedia arguments in sip.conf which instructs it to use network layer information instead the one it got in SDP for communication with an endpoint. Comedia in this case is for media (RTP traffic) and Rport is for signalling traffic.
Straight SDP tampering
If an endpoint during its configuration knows what it’s external address would be it can construct SDP appropriately.
Example.
Asterisk has externip=XXX.XXX.XXX.XXX statement where you can define what address to use in SDP offer.
STUN
But what if you don’t know the external address, or your endpoint doesn’t allow to edit SDP like in p.3. There is STUN for it.
Internal endpoint connect via UDP 3478 to a STUN server in external network. STUN sees how internal endpoint address got transformed by NAT and inform the endpoint about it in reply. So the endpoint can implement SDP fixup with relying on this information.
But in case of symmetric NAT it won’t work because NAT mapping would be different and random when the endpoint start to communicate with another device. Moreover STUN (Simple Traversal of UDP through NAT) is for UDP and not for TCP. And SIP over TCP is more desirable in when SIP messages can be long when implementing video calling and especially video conferencing.
TURN
TURN (Traversal Using Relay NAT) server is a signalling and media relay entity situated outside the NAT in a DMZ. Once an internal endpoint connects to a TURN server it creates a binding of endpoints source address to its routeable interface and informs the endpoint about it. Then it just proxies all media and signalling traffic.
The downside of this approach might be an increased delay and an excessive load on TURN server hardware.
Now TURN is considered as a part of STUN IETF draft.
ICE
Interactive Connectivity Establishment (ICE) allows endpoints decide which address to use for communication. Endpoint are aware of their local IP address, they can get
additional candidates from STUN and TURN servers or by UPnP.
Example
When the remote endpoint receives the list in the SIP INVITE, it replies with a list of addresses obtained in a similar manner. Each endpoint proceeds to attempt connectivity to the addresses provided by the other endpoint by sending STUN messages to each address. In this mode, the endpoints themselves must implement STUN server functionality and respond to STUN request messages from the other endpoint. When an endpoint receives a STUN return message, it knows that it has found an IP address that permits connectivity. Each endpoint chooses the highest-ranked address that offers connectivity to the other endpoint. Then the SIP endpoints exchange INVITE messages again, this time using the addresses obtained during the connectivity-testing phase.
UPnP
UPnP-aware endpoints can make a request to UPnP-aware NATs to open certain pinholes or create bindings, thus making itself aware of routeable public address.
But only a few endpoints (A PC with Windows XP installed being one of them) support UPnP and even fewer NATs do that. Moreover using UPnP presents a possible security risk.
Assent and H.460
Assent is a Cisco proprietary protocol which presents a solution for NAT (and firewall) traversal for H.323 and SIP communications (both signalling and media).
H.460 is an industry standard and a successor to Assent, but is supports only H.323 while preserve the whole idea of Assent.
H.460 consists of three major parts: H.460.17 and H.460.18 for signalling and H.460.19 for media traversal.
In most cases it needs a Traversal client behind the NAT/FW and a Traversal Server in DMZ. In a case your internal endpoints support H.460 (which is rarely the case) you don’t need Traversal client.
These protocols do not need NAT ALG and require NAT to work in symmetrical mode allowing to create bidirectional pinholes.
H.460.17
This method requires a traversal client to establish a RAS tunnel to a traversal server by sending empty H.225 Transport Protocol Data Unit Packets (TPKT) or RAS rerigestrations to it.
When an internal endpoint wants to reach an external one it send signalling (RAS, H.225 and H.245) to the traversal client (a gatekeeper operating in GKRCS mode) which send them over that long-lived tunnel to the traversal server. The same tunnel works in the opposite situation when an external endpoint send signalling to the traversal server which use the tunnel to reach
the traversal client. This tunnel needs only one 1720 port to pass through FW.
H.460.18
This one doesn’t use RAS tunnel as H.460.17. Traversal server use special H.323 RAS Service Control Indication to instruct traversal client to open a pinhole in NAT.
After that traversal client kepps the pinhole open by resending RAS RRQ reregistrations, H.225 or H.245 TPKT.
When an internal endpoint wants to reach an external one it send signalling (RAS, H.225 and H.245) to the traversal client, which relays them to traversal server in DMZ.
The traversal client then maintains NAT binding on behalf of the internal endpoint.
When an external endpoint wants to connect to an internal endpoint, the external endpoint sends a setup message to the traversal server, and then creates a RAS SCI packet that requests that the traversal client send an empty H.225 packet out through the NAT to the traversal server to open a reverse pinhole for the incoming setup message. SCI message gives the client all information about destination ports on the server. So this connection is used to transmit signalling from external endpoint to the internal one.
H.460.19
This mechanism allows traversal server to act as a media relay. It provides H.245 fixup to ensure that only routable addresses are transferred to external endpoint.
When an external endpoint wants to send media to internal network it sends media to traversal client, which in turn sends H.245 message to traversal client which instructs it to send empty RTP packet in return, so NAT binding and a pinhole are created and traversal server and client know what ports to use. H.480.19 do the same to RTCP traffic flow.
Additional feature of H.480.19 is multiplexing, which allows traversal client to use a reduced number of port for RTP. This is done by appending a 4-byte stream number to RTP packet to identify a stream of media.
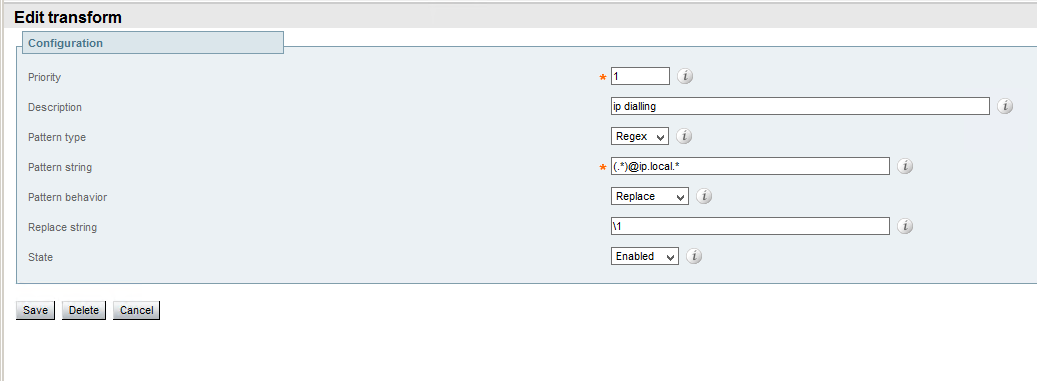
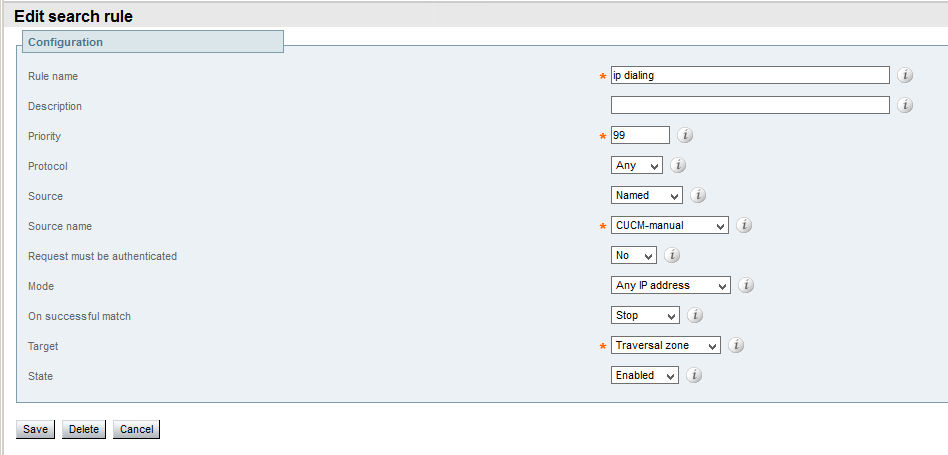
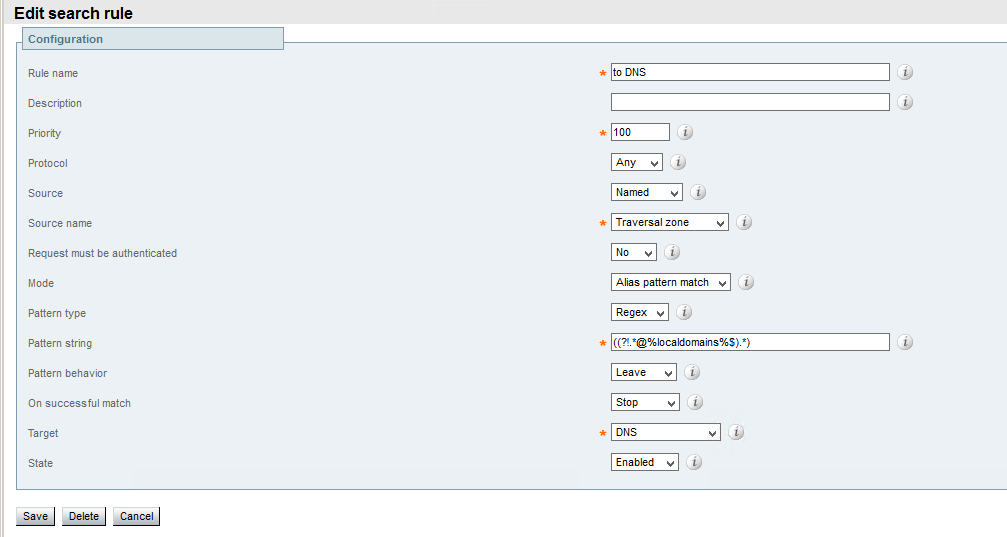
Assent protocol uses the same principles described above and allows SIP communications as well. The only product I know which implements it is Cisco Expressway
(http://www.cisco.com/c/dam/en/us/td/docs/telepresence/infrastructure/vcs/config_guide/X8-6/Cisco-VCS-Basic-Configuration-Control-with-Expressway-Deployment-Guide-X8-6.pdf)